Microservices TechStack

1. Executive Summary
This document outlines a proposal for the upgrade of the existing microservice system . The purpose of this stack is to present the objectives, benefits, scope of work, timeline, and resource requirements for the Microservices system upgrade project. By implementing the proposed upgrade, we aim to enhance the performance, security, and scalability of the system, ultimately improving operational efficiency and supporting its growth.
Microservices are a software architecture approach that structures an application as a collection of loosely coupled, independently deployable services and high cohesion. Each service focuses on a specific business capability and communicates with others through lightweight APIs. This proposal highlights the advantages that microservices offer in terms of scalability, flexibility, resilience, and agility.
The proposed system upgrade encompasses the following key areas:
Health Checks for Application and Monitoring: In this phase, we will assess the current software landscape, identifying any outdated components. We will recommend appropriate upgrades or replacements to ensure compatibility, reliability, and security. This will involve implementing health checks and monitoring mechanisms to continuously evaluate the application's performance and identify potential issues. By proactively monitoring the system, we can address any issues promptly and ensure a stable and secure software environment.
Infrastructure: As part of this upgrade, we will evaluate and upgrade the existing hardware infrastructure to meet the system's performance and capacity requirements. This may involve implementing Domain-Driven Design principles to ensure a modular and scalable architecture. We will also explore the use of an API gateway to enhance security and manage traffic effectively. Additionally, we will investigate the potential benefits of adopting serverless technologies to optimize resource utilization and improve scalability (Domain Driven Design, API gateway, and Serverless)
Traffic Management: In this phase, we will discuss how Istio, a service mesh platform, can enhance traffic management capabilities. Istio provides features such as traffic routing, load balancing, fault injection, circuit breaking, and observability. By leveraging these capabilities, we can improve the system's resilience and ensure efficient traffic distribution, leading to enhanced reliability and performance. We will also explore the application of the Circuit Breaker pattern for effective fault tolerance and graceful handling of service failures. (Circuit Breaker pattern and Service Mesh)
Canary Strategy: Testing on production is a critical aspect of the upgrade process. We will explore the use of Istio and Argo Rollouts to implement canary deployments. Canary deployments allow us to gradually roll out new features or changes to a subset of users or traffic, enabling us to validate the changes in a controlled environment. By carefully monitoring the canary deployments, we can ensure that any issues or regressions are identified early and minimize the impact on the overall system. (Istio & Argo Rollouts )
Chaos engineering: To increase system resilience, we will adopt chaos engineering practices. Chaos engineering involves intentionally injecting failures or unexpected events into the system to test its robustness and identify potential weaknesses. By proactively addressing these issues, we can enhance the system's resilience and ensure it can withstand unforeseen events. We will explore the use of Chaos Mesh or Litmus Chaos, chaos engineering tools, to orchestrate controlled experiments and gain insights into the system's behavior under various failure scenarior
2. Objectives
In this section, I outline the objectives of the system upgrade project. The objectives may include improving system performance, enhancing security measures, ensuring scalability and flexibility, and optimizing the user experience. I align these objectives with business goals and strategic initiatives.
2.1 Health Checks for Application and Monitoring
In today's dynamic and highly distributed application environments, ensuring the availability and reliability of applications is crucial. Kubernetes, a popular container orchestration platform, provides various features to manage containerized applications effectively. One such critical feature is Kubernetes health checks, which enable application monitoring and self-healing capabilities.
There are three types of health checks available in Kubernetes:
Liveness Probe: This probe determines whether an application container is alive and functioning properly. If the liveness probe fails, Kubernetes restarts the container to restore its expected state. Liveness probes are essential for detecting and recovering from application crashes, memory leaks, or other failures that cause the container to become unresponsive.
Readiness Probe: The readiness probe determines whether an application container is ready to receive traffic. It ensures that the container has successfully initialized and is prepared to handle requests. If the readiness probe fails, Kubernetes removes the container from the load balancer, preventing traffic from being routed to it until it becomes ready again. Readiness probes are useful during application startup or when performing maintenance tasks that require temporary unavailability.
Startup Probe: Introduced in recent versions of Kubernetes, the startup probe verifies whether an application container has started successfully. It differs from the liveness probe in that it runs only during the initial startup phase of the container. Once the startup probe succeeds, the liveness and readiness probes take over for ongoing monitoring. The startup probe helps delay the liveness and readiness checks until the application is fully initialized, reducing the possibility of false positives during startup.
In a distributed application architecture, remote healthcheck is common for applications to rely on various remote services such as Databases, APIs, Message brokers, and Redis... Ensuring the availability and health of these dependencies is crucial for the overall reliability and performance of your application. Kubernetes health checks provide a mechanism to manage dependencies on remote services effectively.
When configuring health checks for application containers, we can also include checks for the availability and health of the remote services they depend on. This approach allows Kubernetes to monitor and manage the dependencies, taking automated actions based on the health check results.
When a remote service becomes unavailable or exhibits issues, Kubernetes health checks can detect the problem and mark the dependent containers as unhealthy. This triggers the self-healing capabilities of Kubernetes, such as container restarts or scaling down affected instances
These health checks enable proactive monitoring, failure isolation, intelligent traffic management, and seamless recovery, ultimately ensuring a robust and dependable application environment.
Besides Healthcheck, Kubernetes provides various mechanisms to monitor the state and health of different components within the cluster, including pods, deployments, replicas …, and the Argo CD application deployment tool. We should add more metrics to monitor states, such as:
Kubernetes node not ready
Kubernetes memory pressure
Kubernetes disk pressure
Kubernetes out of capacity
Kubernetes container oom killer
Kubernetes Job failed
Kubernetes CronJob suspended
Kubernetes PersistentVolumeClaim pending
Kubernetes Volume out of disk space
Kubernetes PersistentVolume error
Kubernetes StatefulSet down
Kubernetes HPA scaling ability
Kubernetes HPA scale capability
Kubernetes pod crash looping
Kubernetes ReplicasSet mismatch
Kubernetes Deployment replicas mismatch
Kubernetes StatefulSet replicas mismatch
Kubernetes CronJob too long
Etcd high commit duration
Kubernetes API server errors
Kubernetes API client errors
Kubernetes client certificate expires
Kubernetes networking for Cluster / Namespace / Pod
ArgoCD on-created, on-deleted, on-deployed
ArgoCD on-sync-failed, on-sync-running, on-sync-status-unknown, on-sync-succeeded
Etcd no Leader
Etcd high number of leader changes
Etcd GRPC requests slow
Etcd high number of failed HTTP requests
Etcd HTTP requests slow
Etcd member communication slow
Etcd high number of failed proposals
Etcd high fsync durations
2.2 “Divide and conquer” - Domain-Driven Design, API and API Gateway
Domain-Driven Design (DDD) is an architectural approach that emphasizes designing software systems based on the domain or business problem. It provides a set of principles, patterns, and practices for developing complex software by focusing on the core business domain and modeling it explicitly in the codebase. The key idea behind DDD is to bridge the gap between the business domain and the technical implementation. It encourages collaboration and knowledge sharing between domain experts and software developers to gain a deep understanding of the problem domain
One of the core concepts in DDD is the notion of a "bounded context." A bounded context represents a specific subdomain within the application where a specific set of models, rules, and language apply. By defining bounded contexts, development teams can create modular and maintainable codebases, as each context can be developed independently, reflecting the unique requirements of that specific domain area. Each bounded context can be developed and maintained independently, leading to modular codebases. This modularity improves code organization, simplifies maintenance, and enables teams to make changes to specific domains without affecting the entire system. As a result, DDD helps create software systems that are easier to understand, evolve, and maintain over time.
This model can be thoroughly tested in isolation, ensuring that the core functionality of the system works correctly. By focusing on the domain and employing practices like unit testing and behavior-driven development (BDD), DDD helps improve the overall quality of the software
The design images below show the separation of services according to DDD design. However, in reality, these services are running on the same namespace and only on a few different node groups. This will result in lack of flexibility and difficulties in managing incidents or implementing new technologies
Moving to EKS on AWS allows us to leverage the wide range of AWS services and integrations available, and offers improved scalability, high availability, and managed services. We can easily integrate our own applications with various AWS services such as Amazon CloudFront (CDN), MSK, Secret Manager, and many others with IODC (**)
( * ) : Cluster Autoscaler automatically adjusts the number of nodes in a Kubernetes cluster when there are insufficient capacity errors to launch new pods, and also decreases the number of nodes when they are underutilized.
Autoscaler adjusts the number of nodes by changing the desired capacity of an AWS Autoscaling Group.
(**): OIDC (OpenID Connect) identity provider on Amazon Elastic Kubernetes Service (EKS) is a feature that allows to integration of external identity providers with the EKS cluster for authentication and access control purposes.
2.3 Circuit Breaker and Canary Deployment Strategy (Testing on production)
A Circuit Breaker is a design pattern commonly used in distributed systems to improve resiliency and prevent cascading failures. It acts as a safety mechanism to protect services from excessive load or failures in dependent services. The Circuit Breaker continuously monitors the responses from the dependent service. It tracks metrics such as error rates, latency, and timeouts. The Circuit Breaker defines thresholds for these metrics. If the monitored metrics exceed the defined thresholds, it considers the dependent service to be in a problematic state. Circuit Breaker automatically checks if the dependent service has recovered. If recovery is detected, it restores normal operation without manual intervention
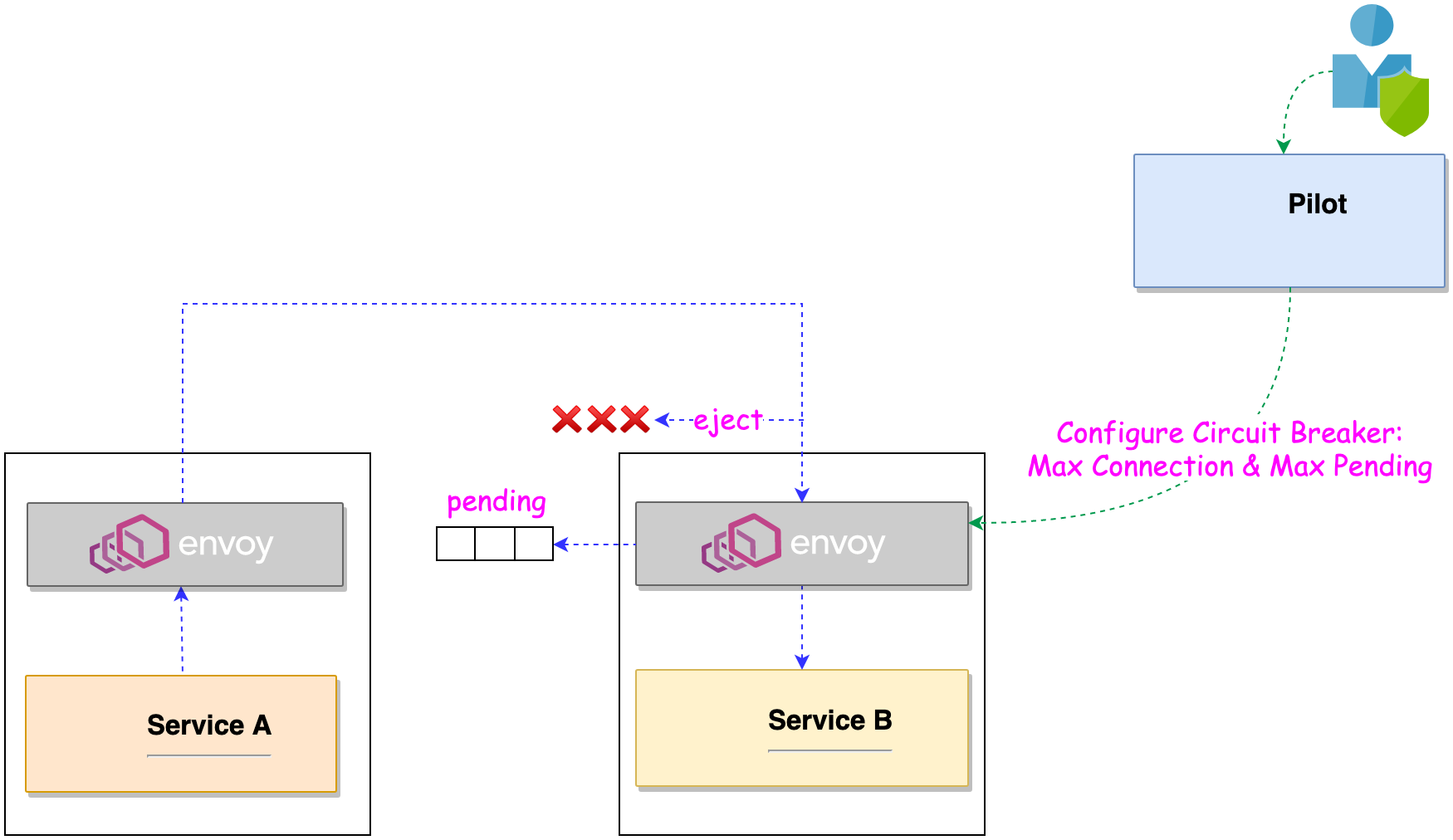
Maximum Connections*: Maximum number of connections to a service. Any excess connection will be pending in a queue.*
Maximum Pending Requests*: Maximum number of pending requests to a service.*
2.3.1 Service Mesh (Istio)
Istio provides a robust implementation of the Circuit Breaker pattern to improve resiliency and fault tolerance within microservices architectures. Istio can configure Circuit Breaker settings for a particular service. This includes defining thresholds for various metrics such as error rate, latency, or concurrent requests.
Istio provides powerful traffic management capabilities that enable fine-grained control over how network traffic is routed, secured, and observed within a service mesh:
Load Balancing: Istio supports various load balancing algorithms, such as round-robin, least connections, and consistent hashing
Traffic Routing: Istio enables advanced traffic routing based on various criteria such as HTTP headers, URL paths, or source IP addresses
Circuit Breaking and Retries: Istio's circuit breaker feature helps protect your services from cascading failures.
Traffic Encryption and Security: Istio provides secure communication between services using mutual TLS (mTLS) authentication. It automatically encrypts traffic within the service mesh.
For example, we can specify via Pilot that want 5% of traffic for a particular service to go to a canary version irrespective of the size of the canary deployment, or send traffic to a particular version depending on the content of the request.

3.3.2 Canary Deployment (Argo Rollouts)
Canary deployment is an advanced technique used to test changes in a production environment by gradually rolling out the changes to a small subset of users before fully deploying them to the entire user base. This allows for real-world testing of the changes, and the ability to quickly roll back the changes in the event of any issues. Canary deployments are particularly useful for testing changes to critical parts of an application, such as new features or updates to the database schema. By using canary deployments, we can ensure that any new changes do not negatively impact the user experience and can fix issues before they affect the entire user base.
Argo Rollouts specializes in managing application rollouts, including canary deployments, blue-green deployments, and other progressive deployment strategies. Argo Rollouts allows you to define canary deployments with fine-grained control over various aspects. You can specify the traffic distribution between the canary and stable versions, set metrics-based validation criteria, and configure rollout-specific parameters such as scaling, rollout duration, and analysis intervals
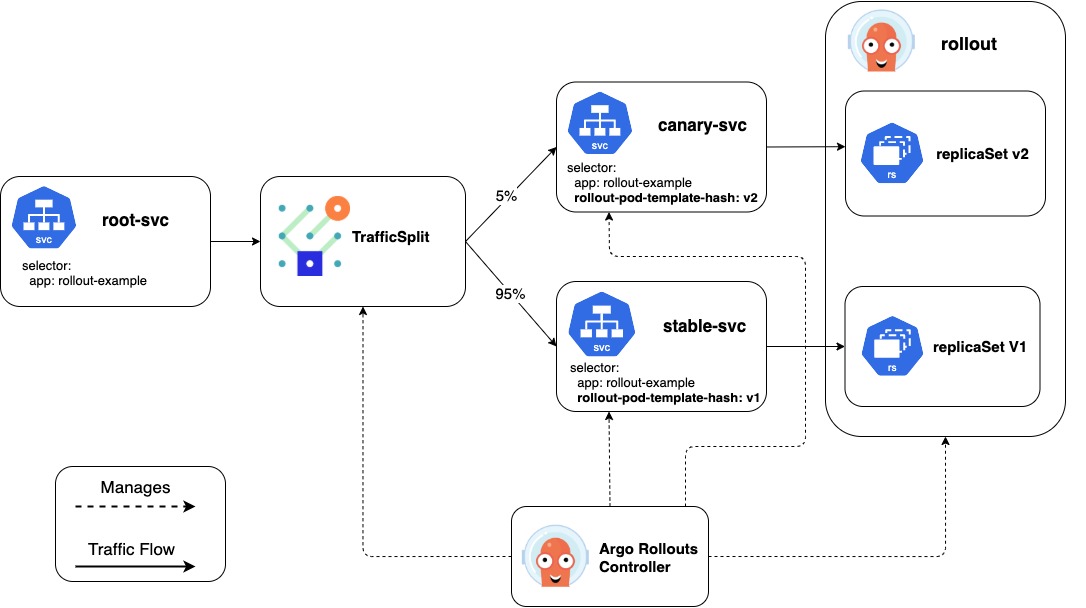
2.3.3 Canary Aggregate
When integrating with Istio, Argo Rollouts supports traffic splitting based on VirtualService and Subset. Istio's observability features, such as distributed tracing, metrics collection, and logging, complement Argo Rollouts' monitoring capabilities. By integrating both tools, we can gain deeper insights into canary deployments
To integrate Argo Rollouts with Istio for traffic splitting, we need to align the configuration of the VirtualService and the traffic routing settings within the Rollout resource.
In the VirtualService, we can define a route rule that specifies the percentage of traffic to be directed to the canary version. For example, can set the
weightfield to 10% for the canary version and 90% for the stable version.
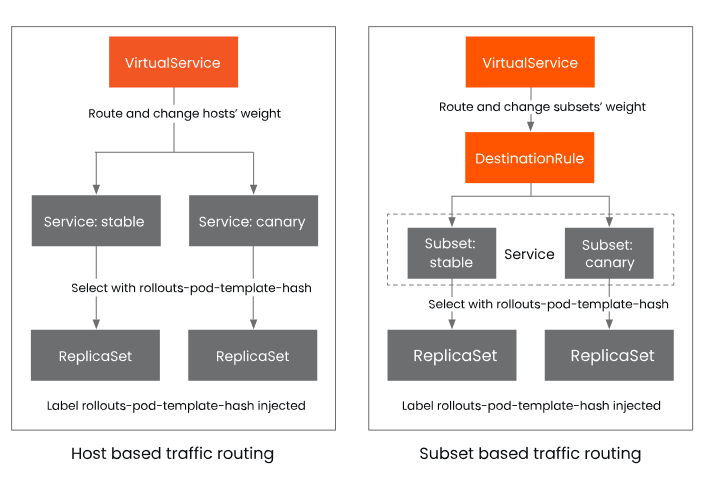
The table below provides a detailed comparison of these two traffic segmentation methods.
| Type | Applicable Scenario | Resource Object | Principle |
| Host-level Traffic Split | Applicable for accessing different versions of services based on hostname; | 2 Services, |
1 VirtualService,
1 Rollout; | Rollout injects the rollouts-pod-template-hash label into the ReplicaSet and selects pods with these labels by updating the selector in the Service; |
| Subset-level Traffic Split | Applicable for accessing different services based on labels; | 1 Service,
1 VirtualService,
1 DestinationRule
1 Rollout; | Rollout injects the rollouts-pod-template-hash label into the ReplicaSet and selects pods with these labels by updating the selector in the DestinationRule; |
3.4 Chaos Engineering (Chaos testing on non-production)
Chaos Engineering is a practice that involves intentionally injecting controlled failures and disruptions into a system to test its resilience and identify potential weaknesses. The goal of Chaos Engineering is not to create chaos for the sake of it but to proactively uncover and address vulnerabilities in a system before they cause unexpected failures or outages in real-world scenarios. Chaos Engineering helps organizations identify weaknesses, enhance system resilience, reduce downtime, build confidence, improve incident response, and foster a culture of reliability
Adopting Chaos Engineering as a practice promotes a culture of resilience within an organization. It encourages teams to think proactively about system reliability, encourages collaboration across various teams (such as DevSecOps, Developers, Operations, and Infrastructure, Architecture, Tester), and fosters a mindset of continuous improvement. By integrating Chaos Engineering into regular development and testing practices, organizations prioritize reliability and build more robust systems.
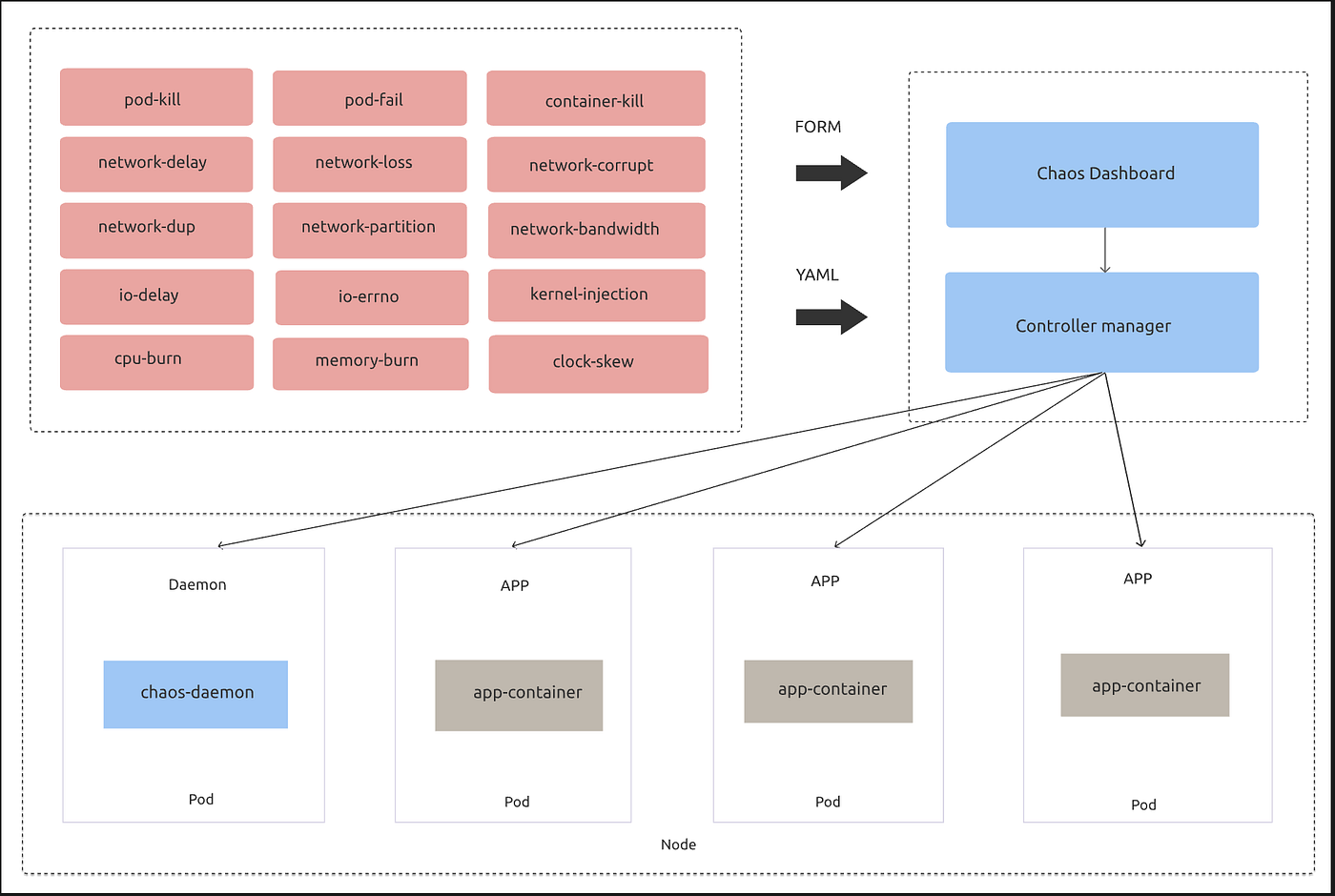
Chaos Mesh and Litmus Chaos are cloud-native Chaos Engineering platform that orchestrates chaos on Kubernetes environments. It can be directly deployed to a Kubernetes Cluster and doesn't require any special dependencies. Some of the important experiments are:
| Experiment Name | Description |
| Node graceful loss/maintenance (drain, eviction via taints) | K8s Nodes forced into NotReady state via graceful eviction |
| Node resource exhaustion (CPU, Memory Hog) | Stresses the CPU & Memory of the K8s Node |
| Node ungraceful loss (kubelet, docker service kill) | K8s Nodes forced into NotReady state via ungraceful eviction due to loss of services |
| Disk Loss (EBS, GPD) | Detaches EBS/GPD PVs or Backing stores |
| DNS Service Disruption | DNS pods killed on the Cluster DNS Service deleted |
| Pod Kill | Random deletion of the pod(s) belonging to an application |
| Container Kill | SIGKILL of an application pod’s container |
| Pod Network Faults (Latency, Loss, Corruption, Duplication) | Network packet faults resulting in lossy access to microservices |
| Pod Resource faults (CPU, Memory hog) | Simulates resource utilization spikes in application pods |
| Disk fill (Ephemeral, Persistent) | Fills up disk space of ephemeral or persistent storage |
3. Benefits
This section presents the benefits will gain from the suggestion. We emphasize the positive impact on performance, security, scalability, and user experience, and how these improvements contribute to overall success. Additionally, we discuss the potential return on investment and long-term cost savings resulting from the upgraded system.
Improved Performance: By implementing advanced infrastructure, software optimizations, and streamlined processes, we will significantly enhance the system's performance, reducing response times and increasing efficiency for both end-users and internal operations.
Enhanced Security: Cybersecurity threats are constantly evolving, and it is crucial to ensure that our system is equipped with the latest security measures. We will implement robust security protocols, encryption mechanisms, and access controls to safeguard sensitive data and protect against unauthorized access.
Scalability and Flexibility: As systems grow, it is essential to have a system that can accommodate increased user demands and adapt to changing business requirements. The upgraded system will be designed with scalability and flexibility in mind, allowing for seamless expansion and customization as necessary.
Improved User Experience: A user-friendly and intuitive interface is paramount to the success of any system. We will focus on optimizing the user experience, ensuring that the upgraded system is easy to navigate, visually appealing, and equipped with features that enhance productivity and user satisfaction.
Resilience: Microservices enhance fault tolerance as failures in one service are isolated and do not affect the entire system. This ensures that can maintain business continuity even in the presence of service failures
4. Scope of Work
This section defines the scope of the system upgrade project. We outline the specific areas that will be addressed, such as hardware and infrastructure, software and applications, and security enhancements. We provide a detailed breakdown of the Techtasks in each area.
Cluster: Amazon Elastic Kubernetes Service
Monitoring: Prometheus stack + Thanos + Grafana + Assert
Alert : AlertManagement
Logging: Loki + promtail + S3 AWS
Scaler: Keda and Metric Server for HPA and AutoScaler for Clusters
Service Mesh: Istio
Canary : Istio + ArgoRollout
Data pipeline: ArgoWorkFollow (Optional: Airflow, Kubeflow)
Ingress Controller: Nginx + ALB Controller (Optional: KongAPI Gateway, Gateway API )
Security: WAF on AWS, IAM OIDC provider
Government: Kyverno
Serverless + CDN: CloudFront
Manifest: Helmchart
CD: ArgoCD (Vault Plugin)
Chaos Engineering: Litmus Chaos (Option: Chao Mesh)
6. Timeline
In this section, we present a comprehensive timeline for the system upgrade project. We divide the project into phases, highlighting the estimated duration for each phase, including system assessment, solution design, implementation, testing, user training, and deployment. The timeline ensures a structured approach and allows for effective project management.
7. Resource Requirements
This section outlines the resources required for the successful implementation of the system upgrade project. We specify the roles and responsibilities of the project team members, including project managers, system architects, developers, quality assurance engineers, and technical support staff. We also discuss the necessary hardware, software, and infrastructure resources.
Update later...
9. Risks and Challenges
This section identifies potential risks and challenges that may arise during the system upgrade project. We assess the impact and likelihood of each risk and propose mitigation strategies to minimize their effects. By proactively addressing risks, we ensure a smoother implementation and reduce any potential disruptions to operations.
Migrating K8S to Amazon Elastic Kubernetes Service (EKS) involves certain risks and challenges. Here are some potential risks and mitigation strategies to consider:
Compatibility and Dependency Challenges: K8s and EKS have some differences in terms of features, APIs, and management processes. Mitigation strategies include:
Conduct a thorough analysis of the K8s environment and identify any dependencies or custom configurations that may require adjustments in EKS.
Evaluate the compatibility of K8s applications and services with EKS and Kubernetes. Update or modify applications and configurations as necessary to ensure compatibility.
Leverage tools and services provided by AWS and K8s to simplify the migration, such as AWS Application Migration Service or K8s Migration Toolkit.
Performance and Scalability: K8s and EKS have different performance characteristics and scalability options. Mitigation strategies include:
Conduct performance testing and benchmarking of the K8s applications and workloads in an EKS environment before the migration.
Evaluate the scalability requirements of the applications and ensure that EKS can handle the expected workload.
Optimize the EKS cluster configuration, such as adjusting instance types, cluster size, and networking settings, to meet the performance and scalability needs of the K8s workloads.
Security and Compliance: Migrating to a new environment introduces potential security risks and compliance challenges. Mitigation strategies include:
Ensure that security best practices are followed during the migration process, such as using secure communication channels, encrypting data in transit and at rest, and implementing strong access controls.
Review and update security policies and configurations to align with AWS security services and best practices.
Conduct a thorough assessment of the compliance requirements for the K8s workloads and ensure that EKS meets those requirements. Implement any necessary additional security measures or configurations.
Cost Management: There may be cost implications associated with migrating to EKS, such as changes in pricing models or resource utilization patterns. Mitigation strategies include:
Conduct a cost analysis and comparison between the existing K8s environment and the proposed EKS setup to understand the potential cost impact.
Optimize resource allocation in EKS based on workload requirements to ensure efficient resource utilization.
Running canary deployments with Argo Workflows and Istio can present certain risks and challenges:
Infrastructure Complexity: Running canary deployments with Argo Workflows and Istio introduces additional complexity to the infrastructure, involving multiple components and configurations.
Canary Workflow Definition: Designing an effective canary workflow using Argo Workflows requires careful consideration of the deployment stages, routing rules, and version validation
Version Compatibility: Canary deployments involve running multiple versions of your application simultaneously, which can introduce compatibility issues and unexpected behavior.
Rollback and Recovery: In the event of issues or failures during a canary deployment, the ability to rollback and recover quickly is crucial.
11. Next Steps
This section outlines the recommended next steps to proceed with the system upgrade project. We suggest arranging a meeting to discuss the proposal in detail, address any questions or concerns, and establish a solid foundation for collaboration.
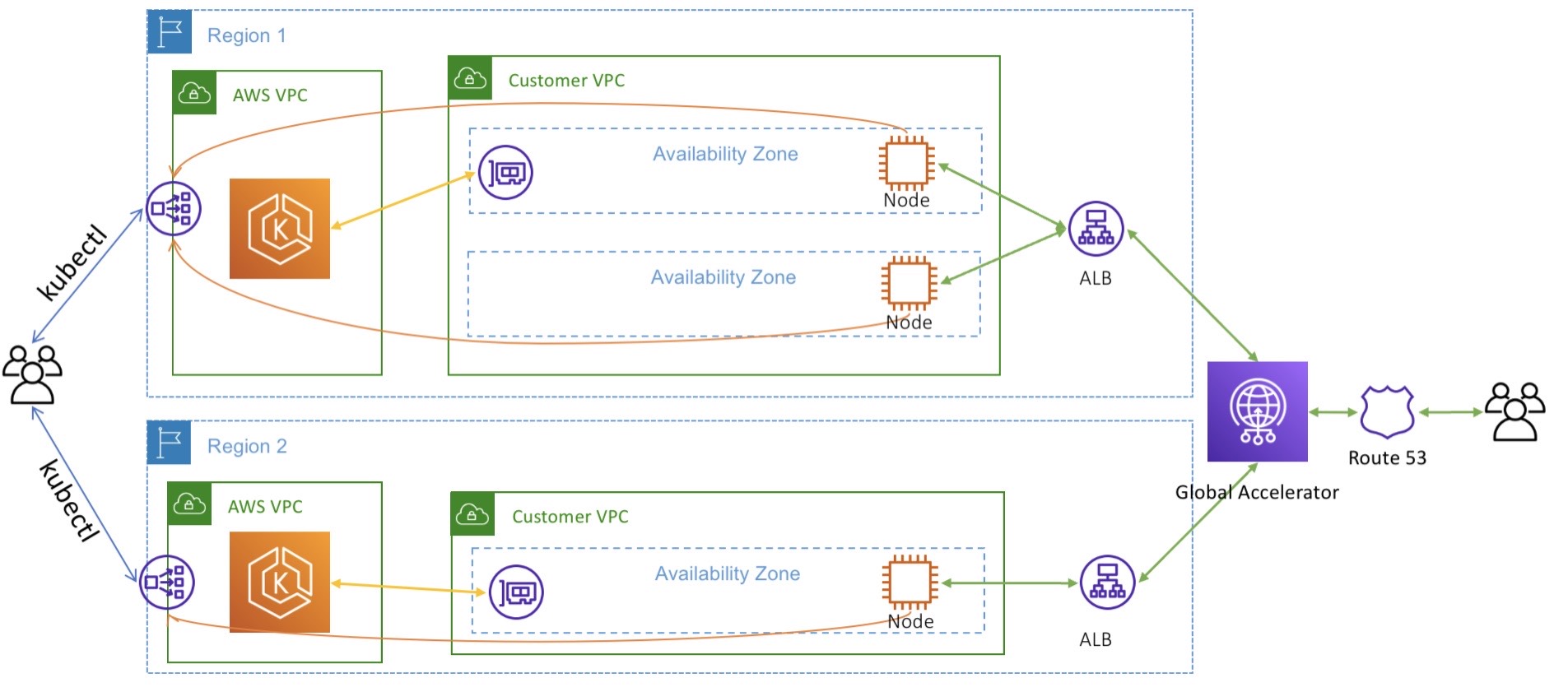
For the long term, we need to update to use multi-cluster with Service Mesh and AWS Global Accelerator. The solution will bring several benefits:
Improved Scalability: With a multi-cluster setup, we can distribute the workload across multiple clusters, allowing for better scalability. Each cluster can handle a portion of the traffic, reducing the load on individual clusters and ensuring that resources are efficiently utilized. This enables horizontal scaling of applications and provides an elastic infrastructure to handle increasing traffic or workload demands.
Enhanced Resilience and High Availability: By employing a multi-cluster architecture, we can achieve high availability and resilience for applications. If one cluster experiences a failure or disruption, traffic can be automatically routed to other healthy clusters, ensuring minimal downtime and uninterrupted service. This redundancy and failover capability provided by the service mesh greatly improves the overall system reliability.
Isolation and Resource Segregation: Service mesh in a multi-cluster setup provides isolation and resource segregation at the cluster level. We can separate different workloads or applications into separate clusters, enabling logical or regulatory isolation. This ensures that resources, configurations, and network traffic are contained within specific clusters, enhancing security and compliance.
Flexible Deployment and Service Migration: Multi-cluster deployments with a service mesh offer flexibility in deploying and migrating services. We can deploy new services or migrate existing ones to specific clusters based on workload requirements, geographical considerations, or other factors. Service mesh provides the necessary mechanisms to handle service discovery, traffic routing, and communication between clusters seamlessly.
12. Appendix
The appendix contains additional supporting information, such as project plans, technical specifications, case studies, and references.
We believe that this system upgrade proposal provides a thorough understanding of the project's objectives, benefits, scope, timeline, resource requirements, and associated costs. We are excited about the opportunity to collaborate with all of teams on this initiative and help drive its success through a technologically advanced system.
For detailed information and further discussions, please do not hesitate to contact us. We look forward to the possibility of working together and contributing growth and prosperity.