Tổng quan về Spark Operator
Giới thiệu
Spark Operator là một công cụ giúp đơn giản hóa việc triển khai và quản lý các ứng dụng Apache Spark trên Kubernetes. Nó cung cấp một cách tiếp cận dựa trên Kubernetes để chạy các công việc Spark (Spark jobs) một cách hiệu quả, tận dụng các tính năng của Kubernetes như quản lý tài nguyên, khả năng mở rộng và tự động phục hồi.
Spark Operator được thiết kế để tích hợp chặt chẽ với hệ sinh thái Kubeflow, giúp các nhà khoa học dữ liệu và kỹ sư dữ liệu triển khai các pipeline xử lý dữ liệu quy mô lớn một cách dễ dàng. Bằng cách sử dụng các Custom Resource Definitions (CRDs) của Kubernetes, Spark Operator cho phép người dùng định nghĩa và quản lý các ứng dụng Spark thông qua các tệp YAML, tương tự như cách họ quản lý các tài nguyên Kubernetes khác.
Trong Spark 2.3, Kubernetes trở thành một backend lập lịch chính thức cho Spark, bên cạnh các bộ lập lịch độc lập, Mesos và Yarn. So với cách tiếp cận thay thế là triển khai một cụm Spark độc lập trên Kubernetes và gửi các ứng dụng để chạy trên cụm độc lập này, việc sử dụng Kubernetes như một backend lập lịch native mang lại một số lợi ích quan trọng như được thảo luận trong SPARK-18278 và là một bước tiến lớn. Tuy nhiên, cách quản lý vòng đời của các ứng dụng Spark, chẳng hạn như cách ứng dụng được gửi để chạy trên Kubernetes và cách trạng thái ứng dụng được theo dõi, khác biệt đáng kể so với các loại workload khác trên Kubernetes, ví dụ như Deployments, DaemonSets và StatefulSets. Kubernetes Operator cho Apache Spark giúp thu hẹp khoảng cách này và cho phép các ứng dụng Spark được định nghĩa, chạy và giám sát theo cách thức đặc trưng của Kubernetes.
Cụ thể, Kubernetes Operator cho Apache Spark tuân theo xu hướng gần đây là tận dụng mô hình operator để quản lý vòng đời của các ứng dụng Spark trên cụm Kubernetes. Operator này cho phép các ứng dụng Spark được định nghĩa theo cách khai báo (ví dụ: trong tệp YAML) và chạy mà không cần phải xử lý quy trình gửi spark-submit. Nó cũng cho phép trạng thái của các ứng dụng Spark được theo dõi và trình bày theo cách thức đặc trưng, tương tự như các loại workload khác trên Kubernetes. Tài liệu này thảo luận về thiết kế và kiến trúc của operator. Để biết thêm về tài liệu của CustomResourceDefinition dùng để định nghĩa các ứng dụng Spark, vui lòng tham khảo Định nghĩa API.
Các tính năng chính
Tự động hóa triển khai Spark: Spark Operator tự động hóa việc tạo, cấu hình và quản lý các tài nguyên Kubernetes cần thiết cho các công việc Spark, chẳng hạn như các Pod cho Driver và Executor.
Hỗ trợ nhiều phiên bản Spark: Hỗ trợ các phiên bản Apache Spark khác nhau, giúp người dùng linh hoạt lựa chọn phiên bản phù hợp với nhu cầu.
Quản lý tài nguyên hiệu quả: Tận dụng khả năng quản lý tài nguyên của Kubernetes để phân bổ CPU, bộ nhớ và các tài nguyên khác cho các công việc Spark.
Khả năng mở rộng: Tự động mở rộng số lượng Executor dựa trên nhu cầu của công việc Spark.
Tích hợp với Kubeflow: Cho phép tích hợp dễ dàng với các thành phần khác của Kubeflow như Jupyter Notebooks, Pipelines và Katib để hỗ trợ các luồng công việc học máy (machine learning).
Giám sát và ghi log: Cung cấp khả năng tích hợp với các công cụ giám sát và ghi log của Kubernetes, giúp theo dõi trạng thái và hiệu suất của các công việc Spark.
Hỗ trợ lịch trình linh hoạt: Cho phép định nghĩa các công việc Spark theo lịch trình (scheduled jobs) hoặc chạy một lần.
Hỗ trợ Spark 2.3 trở lên.
Cho phép định nghĩa và quản lý ứng dụng theo cách khai báo thông qua các tài nguyên tùy chỉnh.
Tự động chạy lệnh spark-submit thay cho người dùng đối với mỗi SparkApplication đủ điều kiện để gửi.
Cung cấp hỗ trợ cron native để chạy các ứng dụng theo lịch trình.
Hỗ trợ tùy chỉnh các Pod Spark vượt ngoài khả năng của Spark thông qua webhook nhập liệu thay đổi (mutating admission webhook), ví dụ: gắn kết ConfigMaps, volumes và thiết lập affinity/anti-affinity cho Pod.
Hỗ trợ tự động gửi lại ứng dụng cho các đối tượng SparkApplication được cập nhật với thông số mới.
Hỗ trợ tự động khởi động lại ứng dụng với chính sách khởi động lại có thể cấu hình.
Hỗ trợ tự động thử lại các lần gửi thất bại với tùy chọn back-off tuyến tính.
Hỗ trợ thu thập và xuất các số liệu cấp ứng dụng cũng như số liệu của driver/executor sang Prometheus.
Architecture
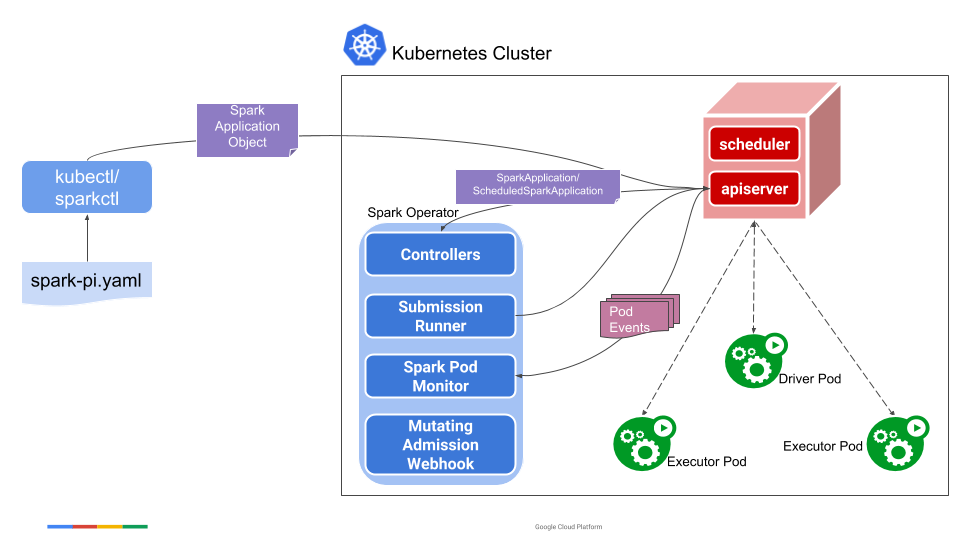
Operator bao gồm:
Bộ điều khiển SparkApplication: Theo dõi các sự kiện tạo, cập nhật và xóa các đối tượng SparkApplication và thực hiện các hành động dựa trên các sự kiện được theo dõi.
Trình chạy gửi (submission runner): Chạy lệnh spark-submit cho các yêu cầu gửi nhận được từ bộ điều khiển.
Bộ giám sát Pod Spark: Theo dõi các Pod Spark và gửi các cập nhật trạng thái Pod đến bộ điều khiển.
Webhook Nhập liệu Thay đổi (Mutating Admission Webhook): Xử lý các tùy chỉnh cho các Pod driver và executor của Spark dựa trên các chú thích (annotations) trên Pod được thêm bởi bộ điều khiển.
Cụ thể, người dùng sử dụng kubectl để tạo một đối tượng SparkApplication. Bộ điều khiển SparkApplication nhận đối tượng này thông qua một trình theo dõi từ máy chủ API, tạo một yêu cầu gửi chứa các tham số spark-submit và gửi yêu cầu này đến trình chạy gửi. Trình chạy gửi sẽ gửi ứng dụng để chạy và tạo Pod driver cho ứng dụng. Khi khởi động, Pod driver tạo các Pod executor. Trong khi ứng dụng đang chạy, bộ giám sát Pod Spark theo dõi các Pod của ứng dụng và gửi các cập nhật trạng thái của Pod về bộ điều khiển, sau đó bộ điều khiển cập nhật trạng thái của ứng dụng tương ứng.
The CRD Controller
Bộ điều khiển SparkApplication, hay còn gọi ngắn gọn là bộ điều khiển CRD, theo dõi các sự kiện tạo, cập nhật và xóa các đối tượng SparkApplication trong bất kỳ namespace nào trong một cụm Kubernetes, và thực hiện các hành động dựa trên các sự kiện được theo dõi. Khi một đối tượng SparkApplication mới được thêm vào (tức là khi hàm gọi lại AddFunc của ResourceEventHandlerFuncs được gọi), bộ điều khiển đưa đối tượng này vào một hàng đợi công việc nội bộ. Từ đó, một worker sẽ lấy đối tượng, chuẩn bị một yêu cầu gửi và gửi yêu cầu này đến trình chạy gửi, nơi thực sự gửi ứng dụng để chạy trong cụm Kubernetes. Yêu cầu gửi bao gồm danh sách các tham số cho lệnh spark-submit. Trình chạy gửi có số lượng worker có thể cấu hình để gửi các ứng dụng chạy trong cụm. Khi một đối tượng SparkApplication bị xóa, đối tượng này được rút khỏi hàng đợi công việc nội bộ, và tất cả các tài nguyên Kubernetes liên quan đến ứng dụng sẽ bị xóa hoặc được thu gom rác.
Khi một đối tượng SparkApplication được cập nhật (tức là khi hàm gọi lại UpdateFunc của ResourceEventHandlerFuncs được gọi), ví dụ, từ người dùng sử dụng lệnh kubectl apply để áp dụng cập nhật, bộ điều khiển sẽ kiểm tra xem thông số ứng dụng trong SparkApplicationSpec có thay đổi hay không. Nếu thông số ứng dụng không thay đổi, bộ điều khiển sẽ bỏ qua cập nhật này. Điều này đảm bảo rằng các cập nhật không thay đổi thông số ứng dụng, ví dụ như những cập nhật do đồng bộ hóa bộ nhớ đệm, sẽ không dẫn đến việc gửi lại ứng dụng. Ngược lại, nếu cập nhật được thực hiện đối với thông số ứng dụng, bộ điều khiển sẽ hủy lần chạy hiện tại của ứng dụng bằng cách xóa Pod driver của lần chạy hiện tại, và gửi một lần chạy mới của ứng dụng với thông số đã được cập nhật. Lưu ý rằng việc xóa Pod driver của lần chạy cũ sẽ chấm dứt lần chạy đó và dẫn đến việc các Pod executor cũng bị xóa, vì driver là chủ sở hữu của các Pod executor.
Bộ điều khiển cũng chịu trách nhiệm cập nhật trạng thái của một đối tượng SparkApplication với sự hỗ trợ của bộ giám sát Pod Spark, nơi theo dõi các Pod Spark và cập nhật trường SparkApplicationStatus của các đối tượng SparkApplication tương ứng dựa trên trạng thái của các Pod. Bộ giám sát Pod Spark theo dõi các sự kiện tạo, cập nhật và xóa các Pod Spark, tạo các thông điệp cập nhật trạng thái dựa trên trạng thái của các Pod và gửi các thông điệp này đến bộ điều khiển để xử lý. Khi bộ điều khiển nhận được một thông điệp cập nhật trạng thái, nó lấy đối tượng SparkApplication tương ứng từ kho bộ nhớ đệm và cập nhật trạng thái tương ứng.
Như được mô tả trong Định nghĩa API, trường Status (thuộc loại SparkApplicationStatus) ghi lại trạng thái tổng thể của ứng dụng cũng như trạng thái của từng Pod executor. Lưu ý rằng trạng thái tổng thể của một ứng dụng được xác định bởi trạng thái của Pod driver, trừ trường hợp việc gửi ứng dụng thất bại, khi đó không có Pod driver nào được khởi chạy. Cụ thể, trạng thái cuối cùng của ứng dụng được đặt thành trạng thái kết thúc của Pod driver khi phù hợp, tức là COMPLETED nếu Pod driver hoàn thành hoặc FAILED nếu Pod driver thất bại. Nếu Pod driver bị xóa trong khi đang chạy, trạng thái cuối cùng của ứng dụng được đặt thành FAILED. Nếu việc gửi ứng dụng thất bại, trạng thái ứng dụng được đặt thành FAILED_SUBMISSION. Có hai trạng thái kết thúc: COMPLETED và FAILED, nghĩa là bất kỳ ứng dụng nào ở các trạng thái này sẽ không bao giờ được thử lại bởi Operator. Tất cả các trạng thái khác là không kết thúc và dựa trên trạng thái cũng như RestartPolicy (được thảo luận dưới đây) có thể được thử lại.
Trong quá trình chuẩn bị một yêu cầu gửi cho một đối tượng SparkApplication mới được tạo, bộ điều khiển phân tích đối tượng và thêm các tùy chọn cấu hình để thêm một số chú thích (annotations) vào các Pod driver và executor của ứng dụng. Các chú thích này sau đó được sử dụng bởi webhook nhập liệu thay đổi (mutating admission webhook) để cấu hình các Pod trước khi chúng bắt đầu chạy. Ví dụ, nếu một ứng dụng Spark cần một ConfigMap Kubernetes cụ thể được gắn kết vào các Pod driver và executor, bộ điều khiển sẽ thêm một chú thích chỉ định tên của ConfigMap cần gắn kết. Sau đó, webhook nhập liệu thay đổi sẽ nhận thấy chú thích trên các Pod và gắn kết ConfigMap vào các Pod.
Handling Application Restart And Failures
Operator cung cấp một tùy chọn có thể cấu hình thông qua trường RestartPolicy của SparkApplicationSpec để chỉ định chính sách khởi động lại ứng dụng. Operator xác định liệu một ứng dụng có nên được khởi động lại hay không dựa trên trạng thái kết thúc của nó và chính sách khởi động lại. Như đã thảo luận ở trên, trạng thái kết thúc của một ứng dụng được dựa trên trạng thái kết thúc của Pod driver. Vì vậy, quyết định này thực chất dựa trên trạng thái kết thúc của Pod driver và chính sách khởi động lại. Cụ thể, một trong các điều kiện sau được áp dụng:
Nếu loại chính sách khởi động lại là Never, ứng dụng sẽ không được khởi động lại khi kết thúc.
Nếu loại chính sách khởi động lại là Always, ứng dụng sẽ được khởi động lại bất kể trạng thái kết thúc của ứng dụng. Lưu ý rằng một ứng dụng như vậy sẽ không bao giờ rơi vào trạng thái kết thúc là COMPLETED hoặc FAILED.
Nếu loại chính sách khởi động lại là OnFailure, ứng dụng chỉ được khởi động lại nếu và chỉ nếu ứng dụng thất bại và giới hạn thử lại chưa đạt tới. Lưu ý rằng trong trường hợp Pod driver bị xóa trong khi đang chạy, ứng dụng được coi là thất bại như đã thảo luận ở trên. Trong trường hợp này, ứng dụng sẽ được khởi động lại nếu chính sách khởi động lại là OnFailure.
Khi operator quyết định khởi động lại một ứng dụng, nó dọn dẹp các tài nguyên Kubernetes liên quan đến lần chạy đã kết thúc trước đó của ứng dụng và đưa đối tượng SparkApplication của ứng dụng vào hàng đợi công việc nội bộ. Từ đó, một worker sẽ lấy đối tượng này và xử lý việc gửi. Lưu ý rằng thay vì khởi động lại Pod driver, operator chỉ đơn giản là gửi lại ứng dụng và để trình khách gửi (submission client) tạo một Pod driver mới.
restartPolicy:
type: OnFailure
onFailureRetries: 3
onFailureRetryInterval: 10
onSubmissionFailureRetries: 5
onSubmissionFailureRetryInterval: 20
Các loại restartPolicy hợp lệ bao gồm Never, OnFailure và Always. Khi một ứng dụng kết thúc, operator xác định xem ứng dụng có cần được khởi động lại hay không dựa trên trạng thái kết thúc của nó và RestartPolicy được chỉ định trong thông số. Nếu ứng dụng cần được khởi động lại, operator sẽ khởi động lại bằng cách gửi một lần chạy mới của ứng dụng. Đối với chính sách OnFailure, operator còn hỗ trợ thiết lập giới hạn số lần thử lại thông qua các trường onFailureRetries và onSubmissionFailureRetries. Ngoài ra, nếu số lần thử lại gửi chưa đạt đến giới hạn, operator sẽ thử lại việc gửi ứng dụng bằng cách sử dụng cơ chế backoff tuyến tính với khoảng thời gian được chỉ định bởi onFailureRetryInterval và onSubmissionFailureRetryInterval, vốn là bắt buộc đối với cả chính sách OnFailure và Always. Các tài nguyên cũ như Pod driver, dịch vụ UI/ingress, v.v., sẽ bị xóa nếu vẫn còn tồn tại trước khi gửi lần chạy mới, và một Pod driver mới sẽ được tạo bởi trình khách gửi (submission client), do đó thực chất là driver được khởi động lại.
Spark Job Namespaces
Giá trị Spark Job Namespaces xác định các namespace nơi các SparkApplication có thể được triển khai. Giá trị của Helm chart cho Spark Job Namespaces là spark.jobNamespaces, và giá trị mặc định của nó là []. Khi danh sách các namespace trống, Helm chart sẽ tạo một tài khoản dịch vụ (service account) trong namespace nơi spark-operator được triển khai.
Nếu bạn cài đặt operator bằng Helm chart và ghi đè spark.jobNamespaces thành một namespace khác đã tồn tại, Helm chart sẽ tạo tài khoản dịch vụ cần thiết và RBAC trong namespace được chỉ định.
Spark Operator sử dụng Spark Job Namespace để xác định và lọc các sự kiện liên quan đến CRD SparkApplication. Nếu bạn chỉ định một namespace cho Spark Jobs, rồi gửi một tài nguyên SparkApplication đến một namespace khác, Spark Operator sẽ lọc bỏ sự kiện đó, và tài nguyên sẽ không được triển khai. Nếu bạn không chỉ định namespace, Spark Operator sẽ chỉ nhận các sự kiện SparkApplication trong namespace của Spark Operator.
Service Account for Driver Pods
Pod driver của Spark cần một tài khoản dịch vụ Kubernetes (service account) trong namespace của Pod, tài khoản này phải có quyền tạo, lấy, liệt kê và xóa các Pod executor, cũng như tạo một dịch vụ headless Kubernetes cho driver. Driver sẽ thất bại và thoát nếu không có tài khoản dịch vụ, trừ khi tài khoản dịch vụ mặc định trong namespace của Pod đã có các quyền cần thiết. Để gửi và chạy một SparkApplication trong một namespace, hãy đảm bảo rằng có một tài khoản dịch vụ với các quyền cần thiết trong namespace đó và thiết lập .spec.driver.serviceAccount thành tên của tài khoản dịch vụ.
#spark-application-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark-operator-spark
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: spark-role
rules:
- apiGroups:
- ""
resources:
- pods
- configmaps
- persistentvolumeclaims
- services
verbs:
- get
- list
- watch
- create
- update
- patch
- delete
- deletecollection
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: spark-role-binding
namespace: default
subjects:
- kind: ServiceAccount
name: spark-operator-spark
namespace: default
roleRef:
kind: Role
name: spark-role
apiGroup: rbac.authorization.k8s.io
Service Account for Executor Pods
Pod executor của Spark có thể được cấu hình với một tài khoản dịch vụ Kubernetes (service account) trong namespace của Pod. Để gửi và chạy một SparkApplication trong một namespace, hãy đảm bảo rằng có một tài khoản dịch vụ với các quyền cần thiết trong namespace đó và thiết lập .spec.executor.serviceAccount thành tên của tài khoản dịch vụ.