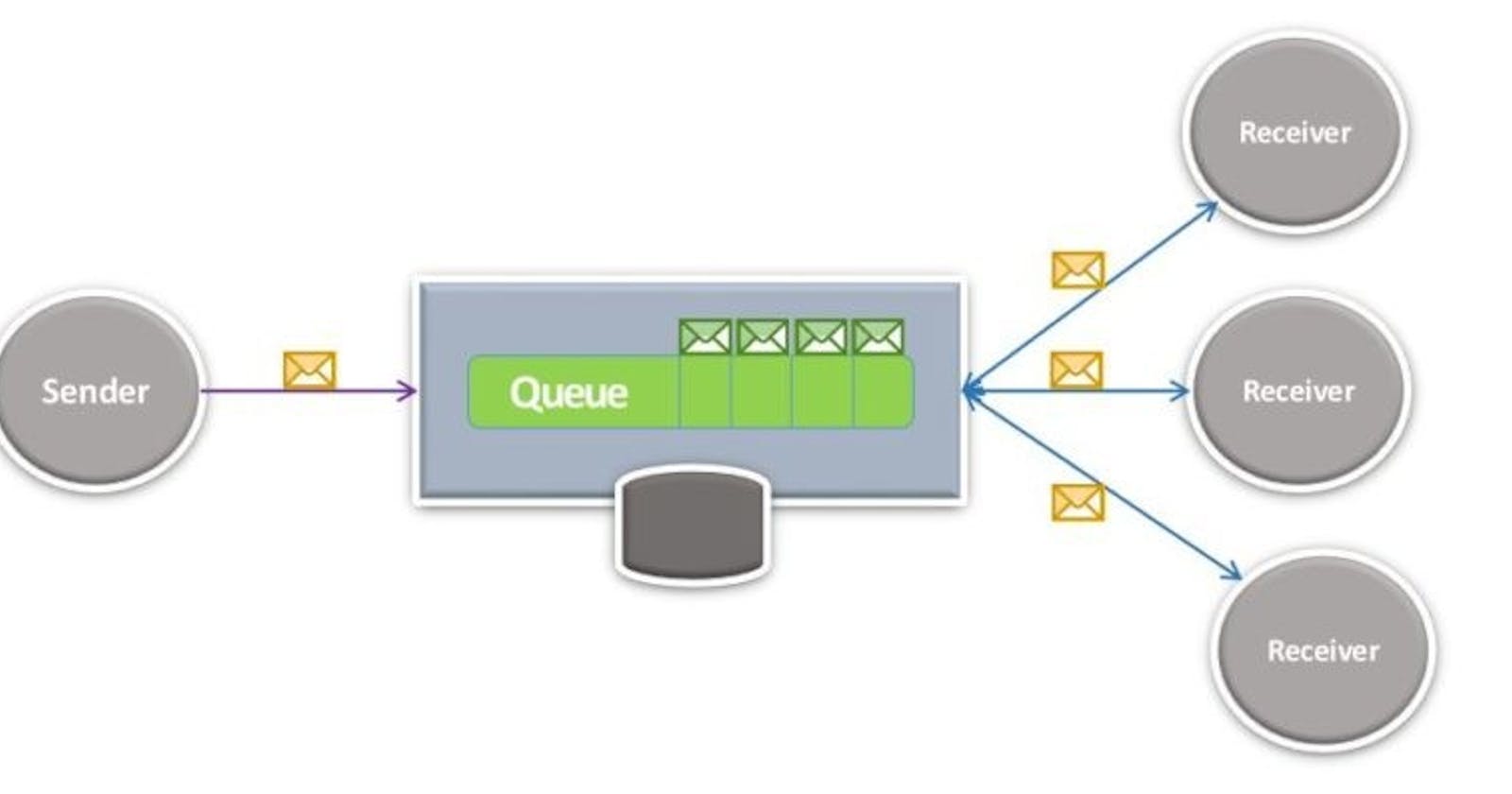


Đôi khi chúng ta cần thực hiện xử lý không đồng bộ như gửi tin nhắn SMS, email, xử lý đơn đặt hàng hoặc truyền thông tin giữa các dịch vụ. Loại xử lý nền này đơn giản không phải là một nhiệm vụ mà hệ quản trị cơ sở dữ liệu quan hệ truyền thống được tối ưu nhất để giải quyết.
Với một message queueing, chúng ta có thể hỗ trợ một lượng lớn các messages đồng thời một cách hiệu quả, messages được đẩy thời gian thực thay vì được kiểm tra định kỳ, các messages được tự động dọn dẹp sau khi được nhận và chúng ta không cần phải lo lắng về bất kỳ sự cố chặn hoặc điều kiện đua. Nói một cách ngắn gọn, hàng đợi thông điệp đưa ra một chiến lược cơ bản vững chắc cho việc xử lý không đồng bộ có khối lượng lớn
Dưới đây là 10 lý do để sử dụng Message Queues:
Tách biệt (Decoupling): Giúp tách biệt các thành phần của hệ thống, cho phép chúng giao tiếp thông qua giao diện được xác định rõ ràng thay vì phụ thuộc chặt chẽ vào nhau. Điều này giúp phát triển các thành phần độc lập và tăng tính linh hoạt của hệ thống.
Mở rộng (Scalability): Do sự tách biệt giữa các thành phần, việc mở rộng từng thành phần riêng biệt trở nên dễ dàng mà không cần thay đổi mã hoặc cấu hình.
Persistence: cung cấp tính năng lưu trữ dữ liệu cho đến khi nó được xử lý hoàn toàn. Điều này giúp đảm bảo dữ liệu không bị mất khi xảy ra sự cố hoặc lỗi hệ thống.
Xử lý lưu lượng đột ngột (Traffic spikes): Bằng cách đặt dữ liệu vào hàng đợi, chúng ta có thể đảm bảo rằng dữ liệu sẽ được xử lý dần dần, ngay cả khi có một lượng lớn lưu lượng truy cập đột ngột.
Giám sát (Monitoring): cho phép giám sát số lượng các messages trong hàng đợi, tốc độ xử lý thông điệp và các thông số khác. Điều này giúp trong việc giám sát và phân tích hiệu suất hệ thống.
Giao tiếp không đồng bộ (Asynchronous communication): cho phép xử lý messages mà không cần phải chờ đợi kết quả ngay lập tức. Điều này giúp tối ưu hóa hiệu suất và tăng tính linh hoạt của hệ thống.
Xử lý lối (Batch processing): hữu ích khi muốn thực hiện xử lý lối, cho phép thực hiện các giao dịch theo cụm thay vì từng giao dịch một. Điều này giúp tối ưu hóa hiệu suất khi xử lý các khối lượng lớn dữ liệu.
Thứ tự (Ordering): duy trì thứ tự của các thông điệp và đảm bảo rằng dữ liệu được xử lý theo thứ tự cụ thể, ví dụ FIFO (First-In-First-Out).
Delivery: messages chỉ được xử lý một lần, đảm bảo rằng không có dữ liệu nào bị mất hoặc được xử lý nhiều lần.
Data flow: giúp giải quyết vấn đề về việc giám sát dòng dữ liệu trong một hệ thống phân tán, giúp xác định các quy trình hoạt động không hiệu quả và cải thiện hiệu suất của hệ thống.